一、DMA简介
DMA(Direct Memory Access,直接存储器访问)技术允许某些硬件子系统直接读写内存,使CPU从数据搬运中解放出来。DMA通常用于进行大量数据的移动,其具体过程为:
- 先由CPU向DMA控制器设定传输指令(源地址,目的地址,大小,猝发长度)
- DMA控制数据转移,CPU转而去做别的工作
- DMA转移数据完毕,向CPU发出中断
- CPU进行中断处理,结束DMA传输
Zynq AXI-DMA是PL端DMA的实现方式。DMA事实上,PS端也有DMA控制器,具体的信息可以在芯片的Technical Reference中查到。大致如下:
| 方法 | 特性 | 问题 | 适用情况 | 速度 |
| PS DMAC | 资源占用少 多通道 逻辑接口简单 | DMAC配置不方便 吞吐量率中等 | PL的DMA资源不够时 | 600MB/s |
| PL DMA配AXI_HP | 吞吐率最高 接口多 HP自带FIFO缓存 | 只能访问OCM和DDR 逻辑设计复杂 | 大块数据、高性能 | 1200MB/s (每个接口) |
| PL DMA配AXI_ACP | 吞吐率最高 延时最低 可选的Cache一致性 | 大块数据传输引起Cache问题 共享CPU互联带宽 更复杂的逻辑设计 | 小块与Cache直接相关的高速传输 | 1200MB/s |
| PL DMA配AXI_GP | – | 吞吐率中等 更复杂的逻辑设计 | PL到PS的控制(一般是AXILITE) PS I/O外设访问 | 600MB/s |
在传输上,AXI DMA利用AXI Interconnect进行数据传输,如下:
简介和示例")
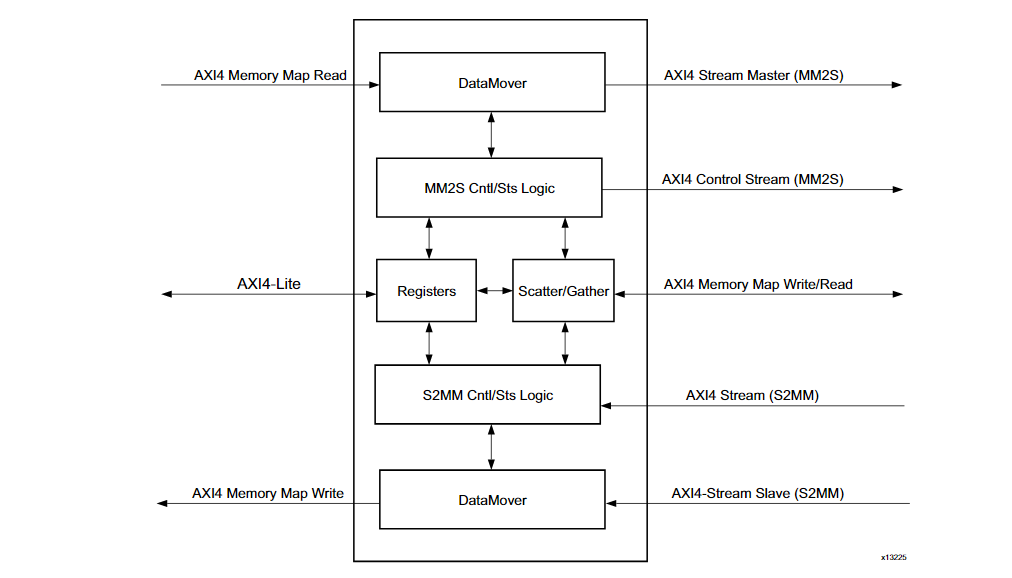
在AXI-DMA IP中,提供了3种存储模式:
- Direct Register (Simple)简单DMA传输,仅需要地址和长度就能进行传输
- Scatter/Gather 允许在单个DMA事务中将数据传输到多个存储区域
- Cyclic DMA 循环DMA,类似于循环队列,待补充
二、从AXI-DMA简单应用中熟悉IP
本Demo利用了AXI-DMA+AXI Stream Data FIFO实现利用DMA从PS读取数据到FIFO,再利用DMA写回PS的过程,没有用到中断,采用轮询请求判断传输结束。
打开Vivado,新建工程。注意选择好芯片或板子的型号,不然在IP Catalog里面可能搜索不到IP.
IP Generator -> Create Block Design
简介和示例")
添加 Zynq IP并Run block Automation
简介和示例")
新建AXI DMA IP
简介和示例")
双击IP进入配置页面,如下所示:
简介和示例")
对部分选项解释一下(详见PG021 AXI DMA P77)
- Enable Scatter Gather Engine 启动Scatter/Gather模式,上面有介绍过,取消勾选变成Direct Register模式,本Demo为简单起见暂时取消勾选。
- Enable Micro DMA 耗费资源少,但是数据传输速度也有所下降,暂时不选择。
- Width of Buffer Length Register:指定用于控制字段缓冲区长度和在Scatter/Gather模式描述符中传输的状态字段字节的有效位数。 对于Direct Register模式,它指定 MM2S_LENGTH 和 S2MM_LENGTH 寄存器中的有效位数。 长度宽度与 Scatter/Gather 描述符中指定的字节数、MM2S_LENGTH 或 S2MM_LENGTH 中指定的字节数直接相关。 字节数等于 2^Length Width。 对于多通道模式,该值应设置为 23。
- Enable Read Channel
- Memory Map Data Width 指定AXI_MM2S位宽(用于从存储器读取数)
- Stream Data Width 指定AXIS_MM2S 数据位宽,应该小于或等于Memory Map Data Width
- Max Burst Size 最大猝发长度,即AXI_MM2S中MM侧的猝发周期最大值。
- Enable Write Channel 同上
经过设置以后,端口减少为以下:
简介和示例")
下面解释端口含义:
- 红色部分(IP控制端口)
- S_AXI_LITE 接收AXI DMA控制器指令(本实验中连接到Zynq的Master AXI GP)aclk是时钟
- 黄色部分(AXI-Stream协议端口)
- S_AXIS_S2MM AXI-Stream Slave端口,获取AXI-Stream数据流并通过M_AXI_S2MM进行Memory Map(写入存储器)
- M_AXIS_MM2S AXI-Stream Master端口,获取从M_AXI_MM2S得到的数据并转换成AXI-Stream协议进行发送
- 剩下两个aclk是各自的时钟
- 绿色部分(中断)
- mm2s_introut mm2s中断,代表指定的长度已经全部作为AXIS发送完毕
- s2mm_introut s2mm中断,代表AXIS的数据已经全部映射到内存
接下来,配置Zynq参数,需要配置的有:
- 使能一个M_AXI_GP用于传输控制数据
- 使能一个S_AXI_ACP或者HP来进行数据高速传输
- 使能中断
简介和示例")
简介和示例")
Run Connection Automation,进行基础连线
简介和示例")
可以先来分析一下这个图:红色部分两个AXI Master和Slave之间的连线,通过AXI Interconnect操作Zynq的ACP端口(黄色部分),实现向Zynq读取/写入数据。绿色部分给AXI DMA IP发送操作指令。
接下来,为了实现本DEMO的目标:PS->DMA->FIFO->DMA->PS,需要例化一个AXI FIFO
在这里我们接受的是AXI-Stream格式的数据,因此选择AXI Stream Data FIFO。
简介和示例")
接下来,将FIFO连接到DMA上。
发现现在DMA IP有两个最关键的端口没有链接:S_AXIS_S2MM和M_AXIS_MM2S,后者是从AXI ACP读到了数据并输出为Stream的端口,因此应该连接到FIFO的S_AXIS端口,前者则相反。连接完成后,再次运行Connection Automation完成时钟和reset的链接。
简介和示例")
为了方便观测信号,设置一个调试模块ILA,搜索ILA,实例化一个System ILA
简介和示例")
我们需要对ILA核进行一些配置来让他可以检测AXI-STREAM协议。双击IP核,首先将端口调整为两个,同时观测FIFO的输入和输出。
简介和示例")
进入Interface Options,修改端口种类为 xilinx.com:interface:axis rtl:1.0 来检测AXI-Stream协议。对于SLOT2同理。接着将ILA连接到FIFO两端进行监控。接下来Run Connection Automation让Vivado完成接下来的连接。
简介和示例")
差点忘了一步:整合中断,在这里DMA有两个中断端口,增加一个Concat IP核来拼接这两个中断并连接到Zynq的中断控制端口上去。(虽然本实验暂时用不到中断)
简介和示例")
点击左侧 Generate Block Design,生成完毕后,在Source面板内右键单击生成的block design,选择 Create HDL Wrapper生成顶层。
进行综合布线,生成比特流,生成后导出硬件描述文件(.xsa)以便进行Vitis IDE开发。
简介和示例")
warning 有关是否包含Bitstream
导出时,往往会询问用户是否要包含bitstream,在本实验中建议不包含。在实际调试过程中,先由vivado进行烧录,配置好ILA的trigger,再用Vitis对ARM核心进行编程,可以准确捕捉数据流向。若包含Bitstream,Vitis会自动重新烧写PL,造成不便。
按照正常方式进行Vitis项目创建,New一个Application Project,选择刚刚导出的xsa文件。后面全部默认,生成一个hello world示例工程。
简介和示例")
下一步,进行代码编辑,这里给出我的代码,修改自官方驱动,在zedboard上测试通过。
#include "xaxidma.h"
#include "xparameters.h"
#include "xdebug.h"
#define DMA_DEV_ID XPAR_AXIDMA_0_DEVICE_ID
#define DDR_BASE_ADDR XPAR_PS7_DDR_0_S_AXI_BASEADDR
#define MEM_BASE_ADDR (DDR_BASE_ADDR + 0x1000000)
#define TX_BUFFER_BASE (MEM_BASE_ADDR + 0x00100000)
#define RX_BUFFER_BASE (MEM_BASE_ADDR + 0x00300000)
#define RX_BUFFER_HIGH (MEM_BASE_ADDR + 0x004FFFFF)
// 最大传输长度
#define MAX_PKT_LEN 0x20
// 初始值
#define TEST_START_VALUE 0xC
//传输轮数
#define NUMBER_OF_TRANSFERS 10
#if (!defined(DEBUG))
extern void xil_printf(const char *format, ...);
#endif
// 主函数
int XAxiDma_SimplePollExample(u16 DeviceId);
// DMA以后检测数据一不一样
static int CheckData(void);
XAxiDma AxiDma;
//设备实例
int main()
{
int Status;
xil_printf("\r\n--- Entering main() --- \r\n");
Status = XAxiDma_SimplePollExample(DMA_DEV_ID); // 调用测试函数
if (Status != XST_SUCCESS) {
xil_printf("XAxiDma_SimplePoll Example Failed\r\n");
return XST_FAILURE;
}
xil_printf("Successfully ran XAxiDma_SimplePoll Example\r\n");
xil_printf("--- Exiting main() --- \r\n");
return XST_SUCCESS;
}
// 测试函数
int XAxiDma_SimplePollExample(u16 DeviceId)
{
XAxiDma_Config *CfgPtr;
int Status;
int Tries = NUMBER_OF_TRANSFERS;
int Index;
u8 *TxBufferPtr; // 等待发送的源地址
u8 *RxBufferPtr; // 要传输的目的地址
u8 Value;
TxBufferPtr = (u8 *)TX_BUFFER_BASE ;
RxBufferPtr = (u8 *)RX_BUFFER_BASE;
// 初始化AXIDMA
CfgPtr = XAxiDma_LookupConfig(DeviceId);
if (!CfgPtr) {
xil_printf("No config found for %d\r\n", DeviceId);
return XST_FAILURE;
}
Status = XAxiDma_CfgInitialize(&AxiDma, CfgPtr);
if (Status != XST_SUCCESS) {
xil_printf("Initialization failed %d\r\n", Status);
return XST_FAILURE;
}
// 检测DMA是否工作在Scatter/Gather模式,下面的代码仅在Direct Resister模式起作用。
if(XAxiDma_HasSg(&AxiDma)){
xil_printf("Device configured as SG mode \r\n");
return XST_FAILURE;
}
// 禁止中断,在本实验中我们不需要用到DMA中断
XAxiDma_IntrDisable(&AxiDma, XAXIDMA_IRQ_ALL_MASK,
XAXIDMA_DEVICE_TO_DMA);
XAxiDma_IntrDisable(&AxiDma, XAXIDMA_IRQ_ALL_MASK,
XAXIDMA_DMA_TO_DEVICE);
Value = TEST_START_VALUE;// 初始化初始值
for(Index = 0; Index < MAX_PKT_LEN; Index ++) {
TxBufferPtr[Index] = Value; // 写入等待传输的TxBuffer
Value = (Value + 1) & 0xFF; // 取后八位,因为定义的是u8
}
// 禁用Cache,防止出现数据一致性问题
Xil_DCacheFlushRange((UINTPTR)TxBufferPtr, MAX_PKT_LEN);
Xil_DCacheFlushRange((UINTPTR)RxBufferPtr, MAX_PKT_LEN);
// 开始传输
for(Index = 0; Index < Tries; Index ++) {
// 配置DMA要写入的目的地址(S2MM)
Status = XAxiDma_SimpleTransfer(&AxiDma,(UINTPTR) RxBufferPtr,
MAX_PKT_LEN, XAXIDMA_DEVICE_TO_DMA);
if (Status != XST_SUCCESS) {
return XST_FAILURE;
}
// 配置DMA要传输的源地址(MM2S)
Status = XAxiDma_SimpleTransfer(&AxiDma,(UINTPTR) TxBufferPtr,
MAX_PKT_LEN, XAXIDMA_DMA_TO_DEVICE);
if (Status != XST_SUCCESS) {
return XST_FAILURE;
}
// Busy的判断取决于AXI Stream的tLast信号
while ((XAxiDma_Busy(&AxiDma,XAXIDMA_DEVICE_TO_DMA)) ||
(XAxiDma_Busy(&AxiDma,XAXIDMA_DMA_TO_DEVICE))) {
/* Wait */
}
// 检测数据一致性
Status = CheckData();
if (Status != XST_SUCCESS) {
return XST_FAILURE;
}
}
return XST_SUCCESS;
}
// 检测一致性
static int CheckData(void)
{
u8 *RxPacket;
int Index = 0;
u8 Value;
RxPacket = (u8 *) RX_BUFFER_BASE;
Value = TEST_START_VALUE;
Xil_DCacheInvalidateRange((UINTPTR)RxPacket, MAX_PKT_LEN);
for(Index = 0; Index < MAX_PKT_LEN; Index++) {
if (RxPacket[Index] != Value) {
xil_printf("Data error %d: %x/%x\r\n",
Index, (unsigned int)RxPacket[Index],
(unsigned int)Value);
return XST_FAILURE;
}
Value = (Value + 1) & 0xFF;
}
return XST_SUCCESS;
}
在运行之前,建议先进行一下Run Configuration
简介和示例")
简介和示例")
确认一下Reset和Program FPGA关闭,不然会重新给PL编程导致ILA断线。
打开Vivado的Hardware Manager,烧写Bitstream到Target
warning 为什么ILA无法识别?
有些情况下ILA可能无法立刻被识别,Vivado的ILA要求有一个自由时钟(供电后立刻起振),少部分情况可能出现烧写完不识别的情况,可以点击一下Refresh device,若还没有,则可以尝试先让Vitis IDE先烧一次再进行refresh。
在Vitis烧写ARM之前,需要先配置一下ILA的Trigger。在本实验中可以看到如下的ILA检测面板
设置如下的Trigger:
简介和示例")
- TREADY信号在数据准备好进行传输的时候置1,因此在FIFO出端进行监听
- TVALID信号在数据准备好接受时置1,因此在FIFO入端进行监听
点击Run Trigger的按钮,再利用Vitis进行数据烧录。
简介和示例")
Vivado ILA成功触发并画出数据:
简单分析一下传输数据:
简介和示例")
红色:当TVALID=1时,握手成功,数据开始传输,直到传输了3*32bit数据后,FIFO出端的TVALID变为1(黄色),数据开始被读出,蓝色部分,最后一个数据被读出后,TLAST被置为1。
为什么是三个周期后开始允许读出?注意到FIFO IP内部有一个CDC (Clock Domain Crossing) sync stages=3,意味着在跨时钟域同步时,要延迟三个周期允许读出,本demo为同时钟域,暂且未考虑此需求。
接着来分析一下传输的数据内容。在Vitis IDE里面设置了初始值为(u8)0xC,以后每个8位数+1,因此传输内容应该为00001100 00001101 00001102 … 事实上为:
简介和示例")
与预期相符。
还发现,单次传输Stream共传输了8拍,一共8*32 = 256bit数据,这是也和事实相符,IDE中设置了传输TxBuffer大小是0x20,共2^5*8bit = 256位。
至此,本实验成功告一段落。
发表回复